Hastad(1986) has shown that O(2d) parameters and points are needed to approximate the so called parity function with d dimensional input by means of traditional machine learning algorithms e.g. Gauss SVM's or FF neural networks. To approximate the same function with a deep neuronal network, O(d) parameters and neurons in O(log2 d) hidden layers are required.
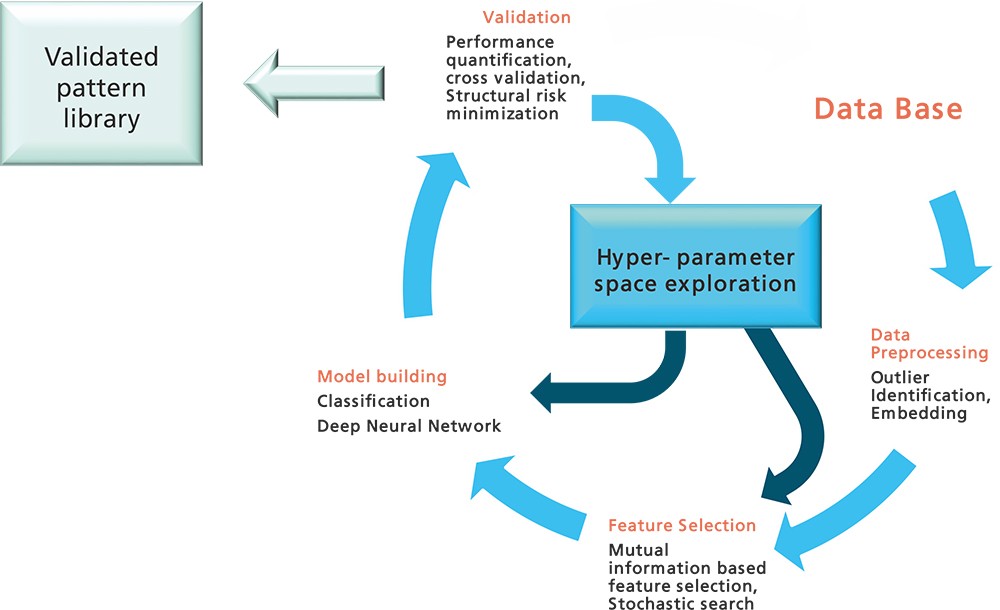
Till 2006 several practice sessions with multilayerd neural networks lead to poorer results (local minima, saddle points, overfitting…) in the gathered test data than shallow neural networks (with 1 or 2 hidden layers). This changed with the discoveries and works of Hinton (2006) and Bengio (2007), who implemented the greedy layer wise pre-training algorithm:
First, every layer of the model is being identified and trained via unsupervised learning (Representation Learning). Thus, every representation of a single layer functions as the input of the next layer. Finally the parameters of all layers are being fine-tuned by means of supervised learning via back-propagation for the purpose of e.g. classification.
 Fraunhofer Institute for Industrial Mathematics ITWM
Fraunhofer Institute for Industrial Mathematics ITWM